Learn how LEIP accelerates your time to deployment Schedule a demo
Learn how LEIP accelerates your time to deployment Schedule a demo

During the last year of our Latent AI Efficient Inference Platform (aka “LEIP”) Evaluation program we’ve had the opportunity to work with many engineering teams from multiple industry verticals to live-test our initial release of the LEIP SDK. Most of these learnings were invaluable and much of the feedback has been incorporated into our just-upgraded LEIP 2.0 release.
Our LEIP 2.0 release is squarely focused on improving the robustness of the LEIP pipeline. As a unique capability of our SDK, the LEIP pipeline removes the challenges and takes the guesswork out of managing and deploying AI models for heterogeneous compute environments. This means that with a single AI/ML pipeline, you can take models trained on TensorFlow and PyTorch and automate model optimization to run production inference on different types of computing devices.
The workflow is as simple as selecting a model as the input to generate an output model ready for production inference
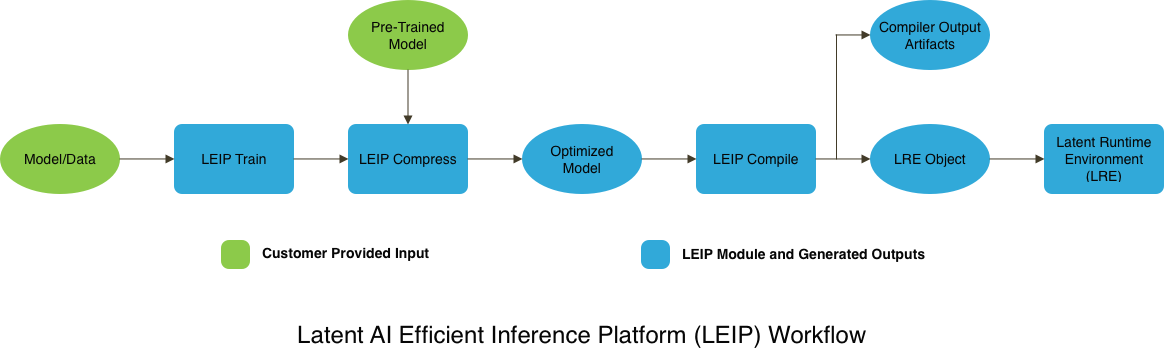
In one of our recent pilot engagements in the manufacturing industry, we leveraged the LEIP workflow to support a single AI/ML pipeline for optimizing AI models for multiple hardware devices. This included a GPU-based computer vision system for product quality control and a mobile device also running a computer vision service for validating machine configurations. We are now focused on optimizing the AI models further to improve the inference speed performance.
LEIP is a unified SDK built for machine learning engineers and AI software developers, working anywhere on the edge continuum, to optimize and accelerate the deployment of AI models for production inference services. LEIP is modular in design enabling developers with the optimization services they need now while providing a flexible foundation to extend the platform with new services for the future.
Today, the LEIP SDK consists of two core modules: LEIP Compress and LEIP Compile. LEIP Compress is powered by state-of-the-art quantization algorithms to automate optimizing trained AI models for efficiency by compressing the millions of parameters that make up today’s advanced AI models to significantly reduce the memory footprint requirements.
LEIP Compile takes the optimized AI model produced by LEIP Compress and automates the generation of compiled code with additional inference performance optimizations that can be targeted for a broad set of hardware devices including servers, PCs, smartphones, surveillance cameras, home automation devices, sensors, and more.
We understand that for many companies, data security is of primary importance. This is why we’ve designed LEIP to run on-premise with your security policies as a priority. LEIP supports integration into existing AI/ML pipelines to provide an automated and unified process for optimizing Al models across a heterogeneous computing environment. LEIP also generates a compression report for each run to provide quantization effect insights for each model. This enables ML engineers to make more informed trade-off decisions between model size and accuracy performance.
As we look downrange our focus will continue to be concentrated on providing improved tooling to help ML engineers and AI software developers optimize AI models for production inference services. This includes additional diagnostic capabilities and management services to easily track LEIP optimization runs. Additionally, we are developing new modules to the LEIP platform to extend the optimization capabilities from the build phase to the run phase. Through our efforts on LEIP Adapt we plan on introducing inference optimization that is intelligent and context-aware to further minimize the compute requirements for performing inference in production.
We’ll have more details on LEIP Adapt very soon.


