

AI agents & edge MLOps: The next big leap in edge computing
AI agents are transforming machine learning operations (MLOps), changing how organizations implement artificial intelligence (AI) models, especially as the focus shifts to edge deployments. Companies now run AI models on edge hardware like smartphones, IoT devices, drones, and autonomous vehicles. This enhances model performance and security and reduces costs by decreasing latency. However, managing MLOps workflows for these edge environments is complex and requires expertise in various hardware and software settings. “The-evolution-of-developer-roles-in-MLOps”]
The evolution of developer roles in MLOps
In the past, deployment and infrastructure tasks were mainly the responsibility of IT teams. With the rise of microservices, the responsibilities shifted to developers through DevOps and DevSecOps. Now, developers are not only creating AI models but also handling MLOps workflows. To achieve optimal model performance, this transition can be particularly tricky in edge AI scenarios, where developers must be familiar with different hardware architectures, such as ARM versus x86 processors or GPU versus neural processing unit (NPU) optimization.
Why agents matter for edge MLOps
AI agents represent a significant advancement in simplifying the deployment of machine learning (ML) models at the edge. Essentially, these agents are AI-driven tools that automate and streamline critical tasks in the MLOps pipeline:
- Model selection and optimization: Agents suggest the best models for specific hardware and performance needs.
- Compilation and deployment: They automate the compilation of models, ensuring they work seamlessly on various edge devices.
- Monitoring and maintenance: After deployment, agents continuously monitor performance, detect data drift, and facilitate model retraining and redeployment without manual intervention.
By utilizing intelligent agents, companies can significantly reduce the manual workload associated with edge MLOps, dramatically speeding up time-to-market.
Real-world impact
Latent AI’s AI agent architecture redefines edge MLOps by focusing on outcomes: faster deployment, seamless scalability, and cost efficiency. These benefits unfold in two key phases: Day 1 (Deployment) and Day 2 (Maintenance & Scale).
Day 1: Simplifying deployment with automation
Traditional MLOps often involves extensive manual tasks: selecting a model, tuning it to fit device constraints, compiling for edge hardware, and validating its performance—a process that can take several weeks.
Latent AI’s agent eliminates bottlenecks. It draws from benchmarks built with over 200,000 hours of device telemetry to automatically select the most suitable model architecture for a given hardware profile. As a result, models can be compiled and deployed in under 48 hours, compared to the usual 6–12 weeks. Proven with the US Navy, where model update time was reduced by 97%, this acceleration means quicker experimentation, faster iterations, and significantly shorter time-to-value for enterprises.
Day 2: Transforming maintenance into momentum
After deployment, many edge solutions encounter issues such as data drift, performance degradation, and a time-consuming maintenance cycle that includes monitoring and redeployment. Latent AI’s agent disrupts this cycle by embedding post-deployment intelligence that monitors how models perform across various devices and settings in real-world scenarios. When Latent Agent detects drift or performance drops, it automatically retrains, retunes, and redeploys models without human intervention.
By intelligently matching models to the constraints of each edge device, the agent ensures maximum hardware utilization. You’re not overpacking inefficient models or underutilizing expensive compute. You’re shipping lean, high-performing models that deliver just the right fidelity, translating to lower latency, lower energy consumption, and fewer failures.
This proactive approach leads to:
- Increased uptime: By addressing issues before they escalate.
- Cost savings: Through optimized model-device alignment and autonomous capabilities.
- Improved performance: By ensuring models are tailored for each edge device, leading to lower latency, energy consumption, and failures.
Latent AI: Leading agentic solutions for edge AI
At Latent AI, our agentic solution gives organizations a significant competitive advantage. We offer not only agent-driven workflows but also a robust technology stack specifically designed for edge scenarios. Here are the key components of our solution:
- Advanced compiler and runtime engines: Our state-of-the-art compiler optimizes model performance for various hardware constraints, while our runtime engines ensure smooth execution across different platforms.
- Embedded security and encryption: We prioritize data integrity and security at the edge with built-in encryption and security measures.
- Comprehensive telemetry and monitoring: Our sophisticated telemetry systems allow for continuous performance tracking and proactive model maintenance.
This approach ensures that organizations can effectively leverage our technology to enhance their operations at the edge.
The Latent AI advantage
Many companies developing for edge AI primarily focus on hardware improvements, emphasizing the benefits of faster models that consume less power. Others concentrate on workflows, utilizing a variety of open-source tools, scripts, and runtimes. However, these approaches often overlook a crucial aspect: scalability.
At Latent AI, we hold a straightforward belief: developers should be able to deploy applications across thousands of devices with diverse hardware architectures while keeping costs and time in check.
Our agent-based architecture addresses this need. By combining automation with (1) enriched data on edge AI solutions and (2) a deeply integrated runtime infrastructure, we empower you to deploy models effectively. We help you scale, monitor, and adapt these models throughout their lifecycle.
Here’s how Latent AI’s agentic solution stands out:
Telemetry-driven intelligence
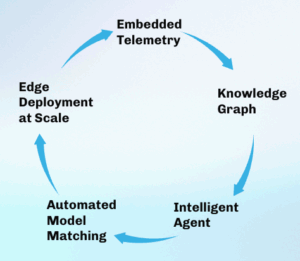
Every deployment contributes to our knowledge graph—over 12 TB of model telemetry and 200,000+ hours of edge compute. Our agent uses this data to:
- Match the best model to the task and hardware.
- Eliminate manual tuning and guesswork.
- Continuously learn from outcomes to make smarter future decisions.
Compile once, deploy anywhere
Our core tooling allows models to be compiled and run across any edge device—any chip, OS, or form factor. Paired with the agent, this becomes a zero-effort deployment engine:
- Model-to-device cycle drops from 6–12 weeks to under 48 hours.
- Enterprises can scale to thousands of edge SKUs without dedicated MLOps.
Adaptive models
Once models are deployed, the agent doesn’t just walk away. It watches. It learns.
- Detects drift, performance decay, or hardware anomalies.
- Automatically retrains, tunes thresholds, or triggers OTA updates.
- Keeps models fresh and accurate—without human intervention.
It creates a flywheel effect:
Looking ahead
The introduction of intelligent agents marks a significant change in how we manage MLOps for edge deployments. Companies that adopt this approach now will see substantial operational efficiencies and gain a strategic advantage in a competitive AI-driven market.
As MLOps practices evolve and deployments grow, using intelligent agents will become essential for organizations that want to stay agile, cut costs, and lead in AI innovation.
Recent Blogs
