

Advanced AI compiler optimization with Forge: A deep dive
In today’s fast-paced environment of AI-driven applications, engineering teams often find themselves at a critical crossroads: how to transform a pre-trained machine learning (ML) model into a high-performing application under tight deadlines. Optimizing the ML model for inference is challenging with the pressing need for quick response times. These challenges are compounded when bringing AI into applications for the edge. The optimization landscape is vast, filled with potential dead ends and sub-optimal solutions. Time is limited, and navigating this complex terrain to uncover the best approach can feel overwhelming. How can engineers balance speed and efficiency effectively while ensuring their applications deliver exceptional performance?
To address the above problem Latent AI has developed Forge, a key technology in our software-hardware AI optimization framework Latent AI Efficient Inference Platform’s (LEIP) Optimize. Forge provides tools for exploring the optimization design space in a systematic and user-friendly manner. Forge includes several post-training quantization options along with a set of compiler optimization settings for multiple hardware targets. For advanced users, Forge enables the implementation of heuristic algorithms to manipulate the ML model representation. For the ML apprentice, Forge automates the complexity required to quantize and optimize to edge hardware manually. In the next section, we will show how Forge works and how it can optimize a pre-trained model.
How Forge works
Forge starts by ingesting a pre-trained ML model from an ML framework such as ONNX, PyTorch, TensorFlow, or LEIP Design and then generates a graph-based internal representation (IR). This IR enables optimizations such as operation fusion, changing the data layout, and hiding memory latency. A user could use this IR to gain knowledge of the complexity of the model even before executing it by inspecting the kind and number of operations present in the graph.
Forge takes the optimized IR and then uses the LLVM compiler to generate a shared object (.so) or emits an ONNX-compatible artifact which can then be loaded into our Latent AI Runtime Engine (LRE) for execution. The figure below shows a block diagram of Forge and how a user would build an application around the compiled artifact.
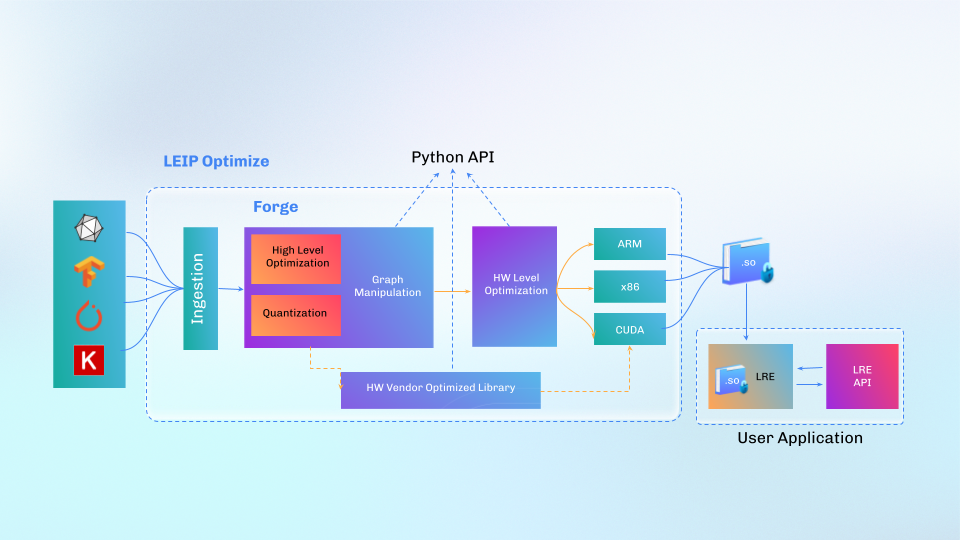
Forge is designed to access all elements of the ML model through the IR. For example, Forge can manipulate the model by inserting, replacing, or deleting parts of the IR that represent operations with the model parameters. Along with Forge’s graph manipulation and hardware optimization, we can optimize a model by changing operators not supported in Nvidia TensorRT to alternative computationally equivalent operators that are supported in hardware. This level of accessibility of the model enables LEIP Optimize for additional use cases beyond optimization.
In the next few sections, we’ll highlight practical examples of how Forge can streamline the work for engineers.
Use case: Introspection
Suppose you have an ML model with unknown functionality and undisclosed expected input/output specifications. With Forge, you ingest the model and then use introspection to learn more about it.
First, you ingest the model:
import forge import onnx onnx_model = onnx.load("path/to/mysterymodel.onnx") ir = forge.from_onnx(onnx_model)
Then you can find the operators in the model as well as inputs and outputs:
# operators in the graph ir.operators # Dict[str, int] # input properties ir.input_count # int ir.input_shapes # List[Tuple[int, ...]] ir.input_dtypes # List[str] # output properties ir.output_count # int ir.output_shapes # List[Tuple[int, ...]] ir.output_dtypes # List[str]
The above example simplifies the task of writing the code to send the correct input shape and data type into your model and read the right number of outputs with their shapes and data types.
With this approach, the number and type of operators give a first-order approximation of the model complexity and also offer insight into potential operators that are not supported on the target hardware. Learn more about model introspection in LEIP Optimize How-to Guides.
Use case: Quantization
Post-training quantization reduces the number of bits associated with the ML model’s weights. This usually means converting from 32-bit floating representations into 8-bit integers, which would yield a 4x reduction in model size and potentially reduce latency if hardware acceleration is present on the target.
There are many quantization algorithms. Forge supports dynamic and static quantization for the bias, activation, or kernels. It also supports symmetric and asymmetric algorithms with some accuracy-boosting techniques, such as per-channel quantization and tensor splitting. Forge support is extensive, and you can find all the details in this link and follow a tutorial that shows how to quantize a Yolov8 model from Ultralytics.
Use case: Hardware Optimization
Suppose you are given an ML model and an NVIDIA GPU that is ready for deployment. However, before you finish your implementation, you’re asked to predict how much slower the model would run on a less powerful NVIDIA GPU.
With Forge, you can easily switch between hardware targets and do a preliminary evaluation of their latencies in a few lines of code:
import forge import onnx from pylre import LatentRuntimeEngine # Import your model onnx_model = onnx.load("path/to/my_model.onnx") ir = forge.from_onnx(onnx_model)
# Compile for HW 1 & do a quick evaluation ir.compile(target="nvidia/geforce-rtx-4090", host="intel/skylake", force_overwrite=True) gx = forge.GraphExecutor("./compile_output/modelLibrary.so", device=”cuda”) gx.benchmark(repeat=10, number=5, return_ms=True) # Compile for HW 2 & do a quick evaluation ir.compile(target="nvidia/nvidia-a100", host="intel/skylake", force_overwrite=True) gx = forge.GraphExecutor("./compile_output/modelLibrary.so", device=”cuda”) gx.benchmark(repeat=10, number=5, return_ms=True) # Load the PyLRE for inference lre = LatentRuntimeEngine(“./compile_output/modelLibrary.so")
Learn more on inference and latency in LEIP Optimize How-to Guides.
Note that you could also target some other hardware platform, like a Jetson Orin or a RaspBerry Pi, which is not the same as the host system. The only requirement there would be to move the compiled binary into the target device and then run the above code using the pylre, our runtime environment for Python. You can find more information about how to do this here. We provide Python runtime environments for several targets and a leaner C++ version of the same runtime environments.
Conclusion
In conclusion, Forge stands out as an essential tool for engineers aiming to optimize pre-trained ML models efficiently. Its systematic approach to compiler optimization and graph manipulation not only simplifies the intricacies of model transformation but also enhances performance across various hardware platforms. By providing robust features like introspection and versatile quantization options, Forge empowers experienced developers and newcomers alike to make informed adjustments that significantly improve inference speed and model efficiency. As the demand for high-performance AI applications continues to rise, leveraging tools like Forge can be the key to unlocking faster, smarter, and more effective ML solutions in an ever-evolving technological landscape. Embrace the power of Forge and take your AI applications to the next level!
Learn more about Forge and LEIP Optimize 4.0
LEIP Optimize 4.0 is available for upgrade to LEIP customers today. To learn more, access our developer documentation or check out product information. If you are new to Latent AI, request a demo today.
Recent Blogs
