



Supercharging AI-assisted data labeling for machine learning models with subject matter expertise
Computer vision AI is reshaping industries, from spotting tumors in medical scans and defects in manufacturing to classifying crops in agriculture and threats in defense surveillance. Its success hinges on high-quality machine learning training data. Labeling thousands of images, videos, or complex datasets is slow, costly, and prone to errors. Training performant AI models demands abundant, accurately labeled data.
Labeling, also known as annotating, is tedious and often involves extensive human effort. For complex data like medical, agricultural, multispectral, or defense computer vision datasets, expert knowledge is critical to ensure precision. AI-assisted data labeling, powered by supervised learning and foundation models, blends automation with human expertise to streamline the process. Tools that empower subject matter experts enable faster, smarter dataset creation for machine learning training. Here’s how it works and why it matters.
Understanding AI-assisted data labeling
Key definitions
AI-assisted data labeling: A hybrid approach where AI tools, often powered by foundation models, automate repetitive labeling tasks while humans refine or validate outputs. This reduces manual effort while maintaining accuracy in machine learning training data.
Automated data annotation: Fully automated labeling where AI applies tags, bounding boxes, or segmentation masks without human intervention. While fast, it struggles with complex or unfamiliar data, like sonar or infrared imagery.
The importance of quality in computer vision datasets
AI models, especially those for computer vision, thrive on vast, accurately labeled datasets. Labeling these datasets can be a bottleneck to deploying edge AI models in production. It can be expensive, time-consuming, error-prone, and often requires a significant amount of manpower. For instance, video data annotation for tracking objects across frames can demand hours of meticulous work. Many other use cases for computer vision datasets, ranging from agriculture to manufacturing and military applications, are highly specialized and demand domain expertise to label the data.
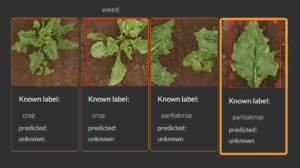
For example, distinguishing a healthy crop from a weed in agriculture requires identifying subtle visual cues, such as leaf texture or color variations. Similarly, detecting microscopic defects in manufacturing or identifying threats in military scenarios, like camouflaged objects in drone footage, hinges on expert knowledge and high-resolution data. The cognitive burden of producing quality labels for these tasks is immense, as errors can lead to missteps. Modern AI-assisted labeling tools aim to ease this burden, enabling humans to label faster and smarter by automating repetitive tasks and leveraging expert input.
Key benefits of AI-assisted data labeling
Recent advancements in generalist foundation models, like SAM (Segment Anything Model) or OWLv2 (Open World Localization), trained on billions of data points, have unlocked a new class of AI-assisted data labeling tools. These tools supercharge efficiency in preparing computer vision datasets with capabilities like:
Object tracking: Automatically relabeling an object (e.g., a moving vehicle) across video frames, slashing the time needed for video data annotation.
One-click labeling: Applying segmentation masks or bounding boxes with a single click, eliminating the need to trace outlines manually.
Model distillation: Labeling user-specified objects (e.g., “crop,” “boat,” “person,” “car”) by leveraging pre-trained models to recognize and tag them instantly.
Enhanced efficiency and speed
By automating repetitive tasks, AI-assisted tools significantly reduce the time required to curate a quality dataset, enabling faster iteration of machine learning models for computer vision. These tools can cut labeling time by up to 70% in some cases, streamlining the development process. Additionally, they lessen the time and workload for experts in producing quality data, especially with unique or complex datasets, enabling faster paths to high accuracy. By minimizing the time domain experts spend on labeling, these tools free them up to focus on high-value business tasks, enhancing overall productivity. Furthermore, AI-assisted solutions reduce the cost of building high-quality computer vision datasets by minimizing manual labeling and subject matter expert (SME) effort, making the process more cost-effective.
Cost reduction
Manual labeling can cost thousands of dollars per dataset, especially for video or specialized imagery. Studies indicate that data labeling can consume up to 80% of the time in an AI project, encompassing data collection, cleaning, and annotation. It’s commonly accepted that one annotator labels 100 bounding boxes per hour, leading to ~10,000 hours for 1 million boxes. For complex tasks, organizations likely require a dataset of 100,000 to 1 million images. AI-assisted tools reduce reliance on human labor, lowering costs while maintaining quality, making deep learning data preparation more accessible. Furthermore, these tools reduce the cost of building high-quality computer vision datasets by minimizing manual labeling and subject matter expert (SME) effort, making the process more cost-effective.
Challenges of trying to label complex data with AI-assisted labeling
State-of-the-art AI-assisted data labeling solutions often struggle to address the complexities of challenging, domain-specific data. Foundation models, despite their extensive training, lack exposure to specialized sensors like sonar, satellite geospatial imagery, or infrared, which are critical in fields like agriculture and defense. For instance:

Unfamiliar domains: Like any other AI model, foundation models are only as good as their training and will suffer when the data domain is unfamiliar. Generalist foundation models are not trained to understand underwater objects in sonar imagery, read an electrocardiogram, or identify manufacturing defects.
Expert dependence: Human labelers require in-depth knowledge to interpret such data, which drives up costs and further slows the process.
Back to square one: When AI tools fail, teams revert to manual labeling, negating the benefits of automation.
To overcome this, AI-assisted data labeling solutions must integrate subject matter expertise in a user-friendly way, enabling non-AI experts to infuse domain knowledge into the system.
Empowering AI-assisted labeling with the knowledge of subject matter experts
SMEs are vital for labeling the complex data that foundation models struggle with. That’s why effective AI-assisted labeling tools include intuitive features that let SMEs guide the system when the data is unfamiliar. These tools maximize the user’s input, so instead of two clicks yielding a single bounding box, those same clicks can generate many bounding boxes when the contents are similar. This way, users gain the speed of automation while preserving the accuracy of human labeling. Key capabilities include:
Feature selection: SMEs can highlight key visual features for the AI to prioritize, improving accuracy in automated labeling. For example, experts can identify the leaf texture of a specific plant, the unique shape of a military vehicle, or the separate components of anchors and chains in sonar imagery.

Dynamic clustering: The system gets smarter when it is presented with examples of SME-prelabeled data. It redraws classification boundaries based on SME inputs, adapting to new labels in real time.


Context clarification: SMEs can provide additional context (e.g., “tanks do not have the long hook while recovery vehicles do”) to refine labeling decisions.
Expert-guided process
Traditionally, an expert-guided process is used at the end of the labeling pipeline for quality checks. We propose flipping this—bring SMEs in early to steer the process. By infusing domain knowledge up front, SMEs increase the likelihood of accurate automated data annotation, reducing costly rework. An agronomist could guide the system to focus on specific weed characteristics, ensuring robust labels for training models. A sonar expert could guide the system to discriminate between underwater mines and lobster pots. With this approach to human-in-the-loop, complex data can be labeled without tying up the bandwidth of the SMEs.
Latent AI’s vision for smarter labeling
Latent AI is pioneering this expert-driven approach, building tools that empower SMEs to enhance AI-assisted data labeling. Latent Assisted Label has been proven in DoW relevant data through the
competitive selection at xTech, the U.S. Army’s program for connecting businesses with Army and DoW experts to build solutions for current problems. Latent Assisted Label’s tools optimize labeling for challenging domains like agriculture, national defense, acoustics, and more. They automate routine annotation to save time, cut costs, and maintain high accuracy, freeing experts to focus on high-value work.
They provide multiple techniques in a single platform, learn from expert input, flag low-confidence results for quick review, and allow experts to refine labels as new data arrives—ensuring datasets are accurate, relevant, and ready for reliable AI deployment. By combining these capabilities into SME-friendly interfaces, Latent AI ensures scalability, efficiency, and security of the models trained with AI-assisted labeled data.
Steer toward a smarter future
AI-assisted data labeling, supercharged by subject matter expertise, is reshaping how we prepare machine learning training data. By empowering subject matter experts to infuse AI systems with their knowledge, this approach unlocks faster, cheaper, and more accurate labeling of complex data—paving the way for smarter AI models everywhere. Ready to streamline your data labeling? Map your data needs, invest in flexible tools, and put experts at the heart of the process. The future of deep learning data preparation is here—let’s make it work smarter.
Recent Blogs
