Learn how LEIP accelerates your time to deployment Schedule a demo
Learn how LEIP accelerates your time to deployment Schedule a demo

There are few things that can increase an organization’s bottom line like an edge AI implementation that delivers on its potential. Imagine a tractor enabled with AI computer vision that needs to limit its speed to 20mph to be able to recognize what is a weed and what is a crop. If the inference speed for weed detection can be increased by only 10%, the actual real-world gains mean the tractor can double its speed to 40 mph while also doubling its production and reducing overall fuel use.
Edge AI is so promising because it can enable organizations to make exponential gains from incremental improvements. The problem is that most organizations are so lured by the promise of AI that they rush past how littered the landscape is with projects that have failed. According to Gartner, only 53% of projects make it to production. In fact, a full 85% of AI projects fail to meet their initial business goals. Those numbers reveal exactly how challenging edge AI implementations are. Because edge AI requires highly optimized models to work efficiently, ML Engineers have to go through a frustrating process that includes:
We knew organizations needed a way to improve their odds of edge AI success. We realized that by automating the ML optimization pipeline that we could resolve edge AI deployment challenges and let organizations instead focus on their business outcomes. We created the Latent AI Efficient Inference Platform (LEIP) to empower AI developers with adaptive, on-premise software tools that can compile, compress, and deploy AI models for any hardware target, framework, or OS.
While LEIP provides ML engineers with everything they need for success, the process still requires configuration to get the best results. Quantization algorithms (symmetric vs asymmetric vs tensor-based vs channel-based, etc.), data layouts (channel-first-NCHW vs channel-last-NHWC), and compiler optimizations (graph partitioning, operator fusion, math kernel selection) all have to be configured while additional techniques like Tensor Splitting and Bias Correction often have to be added.
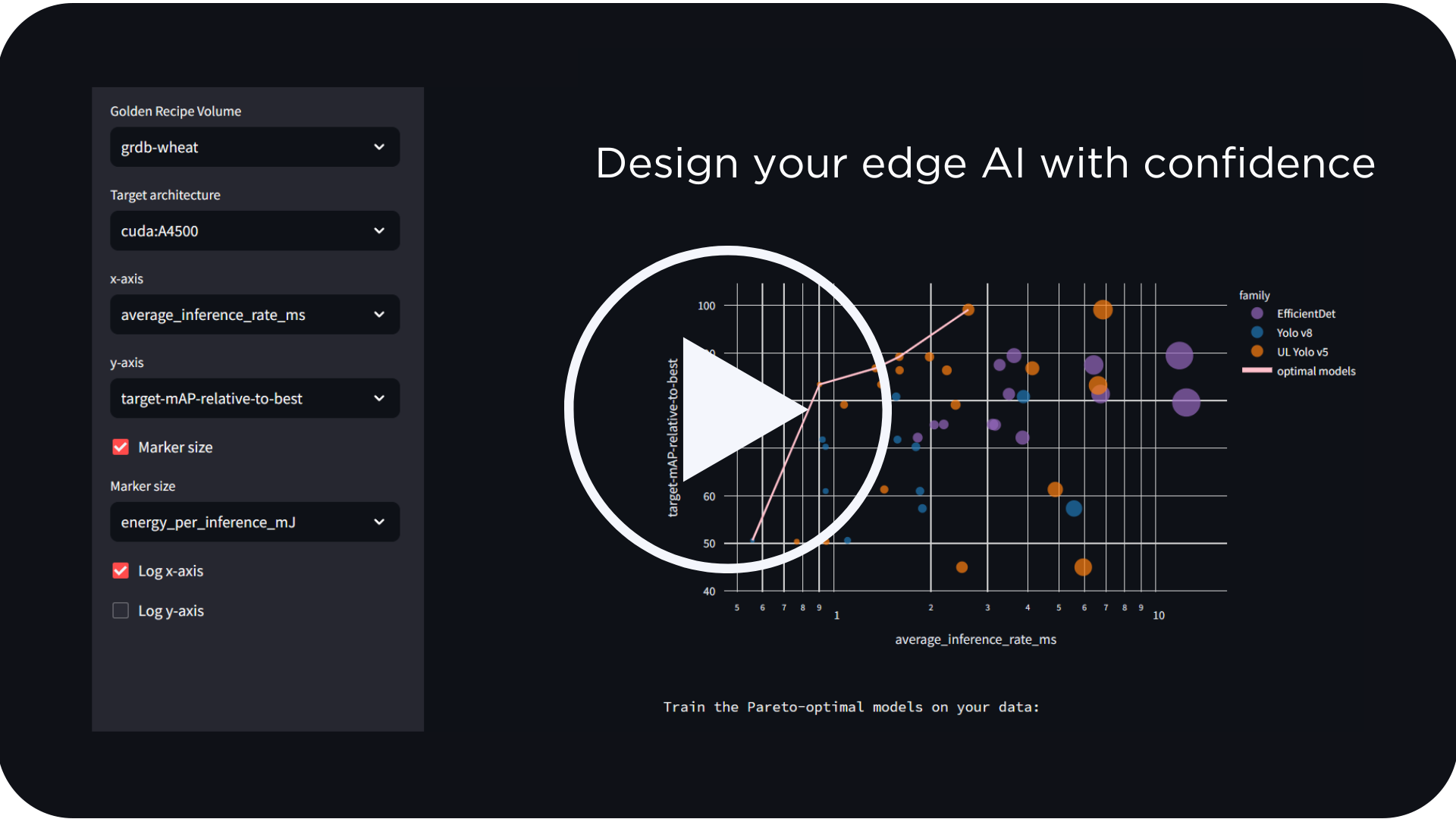
We knew we wanted to go further to help our customers succeed. We created Latent AI LEIP Recipes to take the stress out of Edge AI deployments. Latent AI LEIP Recipes are a set of pre-configured assets combined with a set of instructions to follow to get to an optimized model. Each LEIP Recipe tackles a type of problem like object detection or classification and is configured for a specific model and hardware target. It comes with all the model optimization settings pre-configured including quantization, structured pruning and throttling, and lets ML engineers leverage models pre-optimized for low-power, inference speed, size and memory.
Because our goal is to ensure your Edge AI projects can drive timely business decisions, one of our key performance metrics is your time to market. A typical ML Engineer spends considerable time resolving the ML model into a format that can run on the hardware. Without accounting for training time, it can take up to 3 days to deploy a standard object detection model like the YoloV5 large when optimized using Nvidia TRT libraries to an AGX. However, a LEIP Recipe can accelerate your time to market by 10x by reducing this process to a few hours.
With LEIP Recipes, ML engineers focus on optimization using pre-configured settings on the LEIP SDK. LEIP Recipes have several other advantages including:
For organizations who need a better way to implement AI than the cloud can offer, Latent AI Recipes enable Edge AI solutions with reduced power, latency, and memory footprints while maintaining model accuracy. LEIP Recipes can help you overcome the steep challenges edge AI presents and bake in a plan for success. To learn more about how LEIP Recipes can help you gain actionable, reliable, and repeatable insights from your data, or to inquire about a specific configuration, contact us at info@latentai.com.

Watch how LEIP helps you start training computer vision models in minutes instead of months