


Post-training watermarking for machine learning models

Once considered black boxes, machine learning (ML) models are gradually revealing their inner workings. As our blog, ‘Generative AI: No Longer A Black Box,’ highlighted, understanding how AI makes decisions is crucial for improving and protecting these models.
The need for robust security measures is even more critical in edge AI, which operates in often remote and resource-constrained environments. Edge devices, unlike cloud-based systems, are physically exposed and more susceptible to various attacks.
Like the film industry’s reliance on watermarks to protect copyrighted content, watermarking ML models can safeguard a company’s competitive advantage. Preventing unauthorized model usage will allow companies to protect revenue streams and maintain market leadership. By embedding a unique digital signature within the model, organizations can track ownership, gain insights into internal operations, and protect against theft and tampering.
The Growing Threats to Machine Learning Models
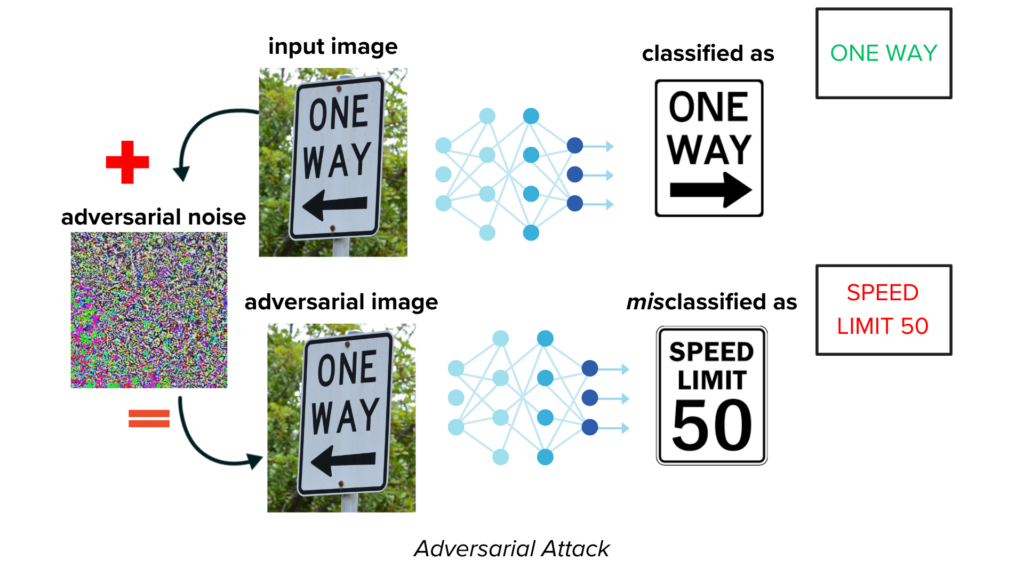
Figure 1. Example of an adversarial or input manipulation attack on an image classification model. While the original model successfully classifies the input image as a one way sign, it misclassifies it as a speed limit sign when an adversary adds noise to the input.
Attacks on ML models can be generalized into three categories:
- Training Data Attacks (Data Poisoning Attacks): Adversaries manipulate a model in the training stage by introducing corrupted or misleading information into its training data; this causes it to make inaccurate predictions or behave in an undesirable way.
- Input Manipulation Attacks (Adversarial Attacks): Similar to training data attacks, attackers craft specific inputs designed to fool an already trained model, leading to incorrect outputs or unexpected behavior (see example in Figure 1).
- Model Stealing Attacks (e.g. model inversion and model theft): Adversaries attempt to extract information about a model’s structure, parameters, or training data by training models that invert the predictions of a target model or by stealing a target model entirely.
The Need for Watermarking
Adversaries use training data and input manipulation attacks to alter a model’s performance, parameters, and behavior. Approaches to improve security against these specific attacks require regulating and controlling training data or redesigning a model for more robust testing. Watermarking, though, is an effective measure against model stealing attacks. Watermarking is a security technique for identifying model ownership and protecting an entity’s intellectual property (IP). It allows a user to trace the source of a model and prove ownership, which facilitates protection and reduces the likelihood of model theft.
Watermarking involves embedding a signature or hidden signal into a component of a model’s architecture that minimally affects its performance but makes it easy to establish its owner when retrieved. Akin to physical watermarks like a stamp or signature, digital watermarking ranges from simple encoded messages and digital logos to UUIDs and checksums of data. Watermarking in ML models, specifically neural networks, can be implemented in different ways depending on the model’s stage of development (see Figure 2).

Figure 2. Watermarking methods in various stages of the MLOps Pipeline. Image loosely based on Boenisch, F. (2021, November 9). A Systematic Review on Model Watermarking for Neural Networks. Frontiers in Big Data, 4, 729663.
A developer can use training data to watermark a model by creating a trigger dataset consisting of selected points that have been watermarked from an original training set. They then train a model on the original data and this watermarked “trigger” data to have the model produce unexpected outputs when inputs from the trigger dataset are fed in. Developers can use the model’s output as a signature to determine if their model was stolen by feeding the trigger data into an allegedly stolen model and seeing if it produces the same, unexpected output. During training, a developer could also entangle a watermark with the model’s weights as they recalculate them. While undetectable and effective, these watermarking methods may be impractical for an already trained model. If the model is not watermarked during the data or training stages, a developer would need time and resources to retrain or redesign their model to acquire a signature.
Post-Training Watermarking with Latent AI
An alternative to making an in-training watermark is to insert it after training, and there are different approaches to doing it (see Figure 2). For example, one method is to embed a watermark, or signature, into the weights and biases of the model’s layers via the least significant bits (LSBs). Another approach is to modify the model’s graph structure by splitting tensors or inserting identity layers with the signature. Lastly, similar to a visual signature or symbol on an image, a watermark can be directly embedded into the output of an ML model as part of the results. There are many approaches that Latent AI is exploring, including some that are more covert, and they are enabled with our MLOps tools that can add watermarks to a model post training.
Latent AI Efficient Inference Platform (LEIP) has a new capability for ML engineers to internally access a model for diagnostics, introspection, and performance enhancements. It enables direct manipulation and modification of a model’s graph after training, allowing for rapid adjustments to model weights and layers, as well as the precise addition or removal of nodes at any point in the graph. Furthermore, it supports automation and scalability for operations and modifications to models of all sizes. With this capability, developers can also implement post-training watermarking and other security techniques in their models.
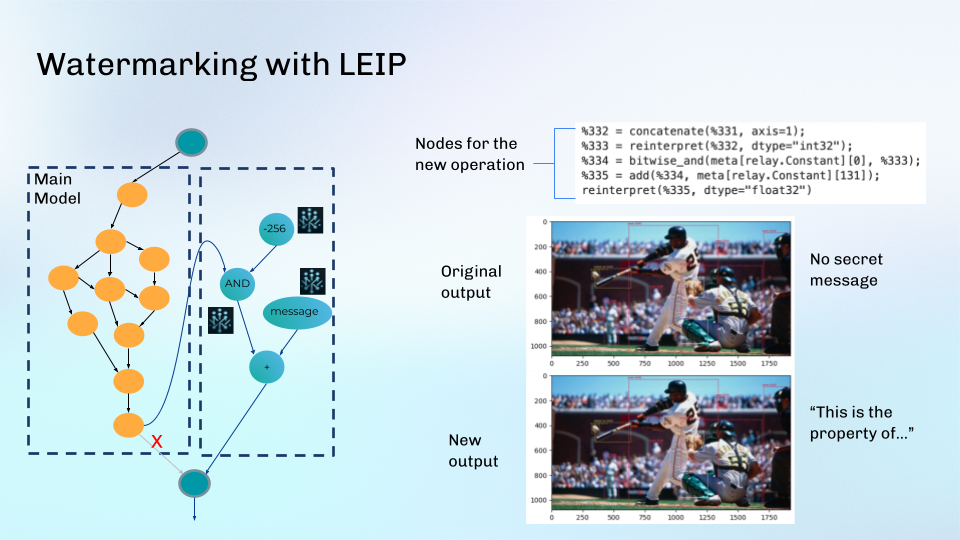
Figure 3. Example of watermarking with LEIP on a Yolov8s object detection model. Using LEIP, a developer can modify the model’s layers (left) and embed a distinct, hidden signature in the outputs. Compared to the original (top right), this signature minimally affects the model’s accuracy and performance (bottom right).
Watermarking with LEIP can be done in different ways. First, our capability can embed or overwrite a traditional, signature-like watermark into a model’s outputs with few operations (see Figure 3). The modified model will maintain the same performance as the original but include a developer-chosen watermark (e.g., a copyright or licensing statement) that can identify its ownership and prevent model theft. Additionally, our capability can calculate and append checksums to a model’s predictions, improving output integrity and identity protection. These security techniques remarkably strengthen the model’s defense against adversaries attempts to corrupt the model output. Our solution also has built-in functions that can recognize when data poisoning attacks have corrupted models based on detecting changes in the models’ weights and graph structures.
LEIP Empowers AI Security and Trust
Latent AI’s surgical capability for modifying ML models post-training makes watermarking and ML security much more accessible for developers. Our technology can quickly extract nodes or parameters from the model and precisely insert, delete, or alter new and existing operations to bolster security for models at scale. Its greatest advantage, though, is it allows ML engineers to add different security features to their pre-trained models and deploy them without retraining. This will save developers tremendous time and resources as they won’t have to worry about security in training and will have the versatility to add it post-training.
As AI becomes more pervasive, the commercial value of ML models will skyrocket. To safeguard this intellectual property, robust security measures are essential. Model theft, unauthorized replication, and intellectual property infringement significantly threaten a company’s bottom line.
Just as the film industry relies on watermarks to protect copyrighted content, watermarking ML models is a critical step in safeguarding their value and maintaining a competitive edge. Latent AI’s technology empowers businesses to establish clear ownership, deter piracy, and preserve the value of their ML assets.
Recent Blogs
