



Reduce your AI/ML cloud services costs with Latent AI

Cloud computing offers more operational flexibility than privately maintained data centers. However, operational expenses (OPEX) can be especially high for AI. When deployed at scale, AI models run millions of inferences which add up to trillions of processor operations. It’s not just the processing that’s costly. Having large AI models also means more storage costs. And with more data coming, those costs are only going to rise.
How to lower your OPEX with LEIP
The Latent AI Efficient Inference Platform (LEIP) is an all-in-one AI development kit that empowers developers to quickly and easily design, optimize and deploy AI to a variety of edge devices–at scale. LEIP can significantly lower your recurring OPEX by optimizing model runtimes for improved inference at smaller sizes. LEIP can provide additional cost savings when making the AI/ML model portable across different hardware.
Amazon SageMaker Benchmarking Study shows improved inference at lower costs
A recent benchmarking study compared models optimized with SageMaker alone versus those optimized with SageMaker and LEIP together. By using more efficient processing, LEIP reduced the size of SageMaker models and transformed their computation workload. As a result, inference costs were dramatically lowered.
When compared to Amazon SageMaker alone, LEIP increases your cloud performance while reducing your OPEX.
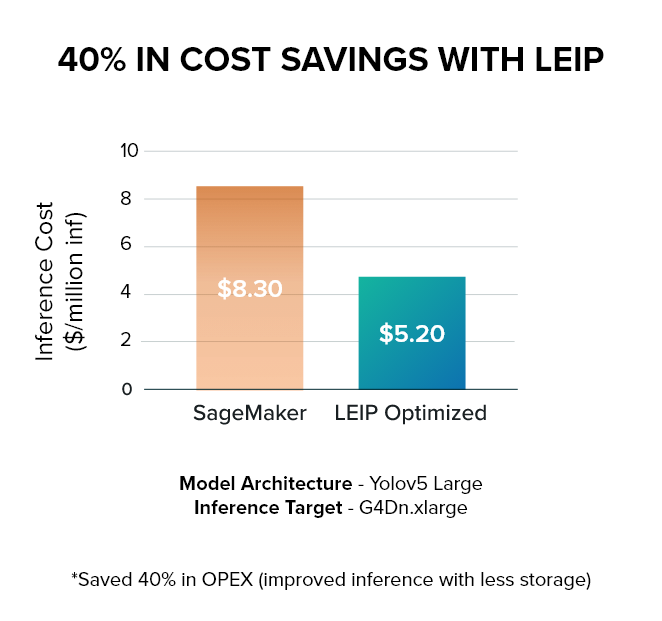
LEIP optimized models:
- Saved 40% on OPEX (improved inference plus less storage)
- Increased edge inference by 66% and cloud inference by 48%
- Reduced storage requirements with 10x smaller edge models
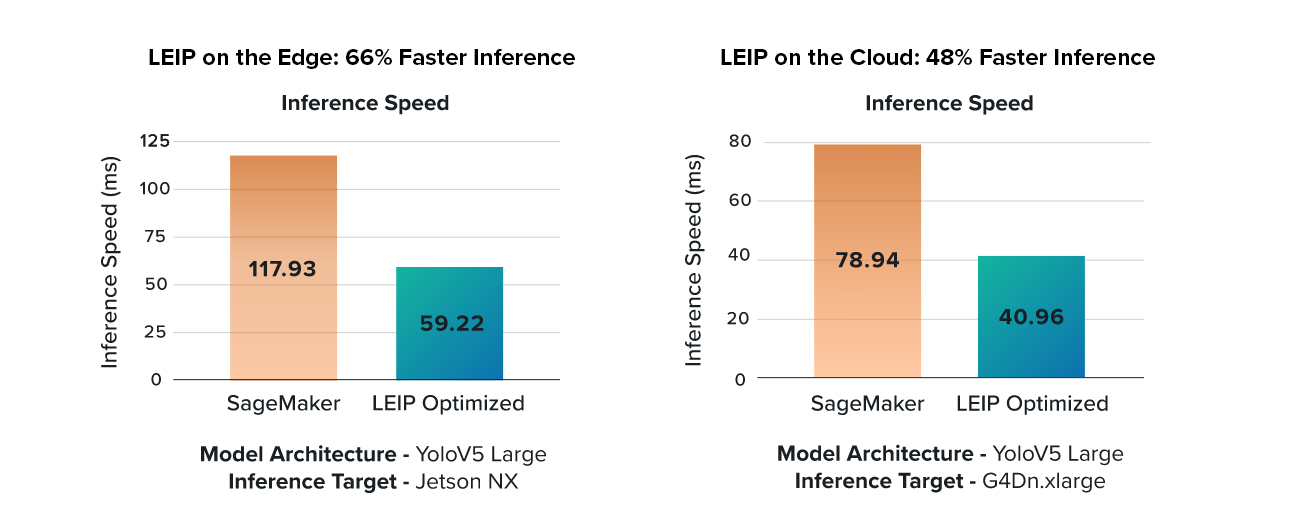
LEIP on the edge: 66% Faster
With only a negligible loss in accuracy, a LEIP optimized AI model offers 66% faster inference speed when compared to SageMaker models alone. The study used a Yolov5-large object detection model targeting an embedded NVIDIA Jetson NX processor.
Cloud-based LEIP: 48% Faster Machine Learning
A LEIP optimized AI model offers 48% faster inference speed on an AWS processor instance (G4Dn.xlarge) with only a negligible loss in accuracy. LEIP not only offers performance portability, but also model optimization to provide the most efficient acceleration of the AI model runtime. LEIP can also optimize AI models for other target hardware with only a simple command line change.
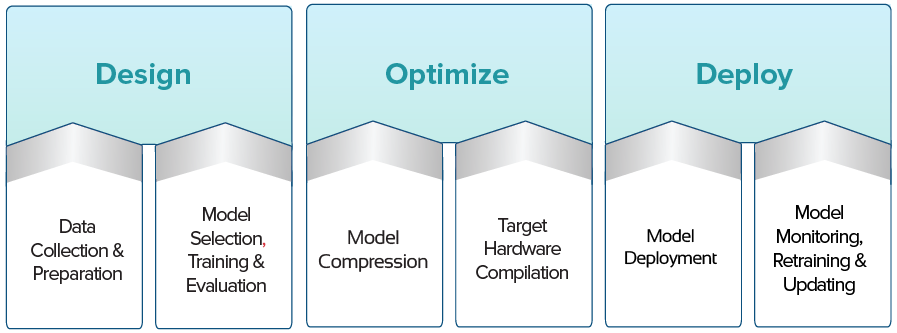
Faster time to market with LEIP end-to-end MLOps
LEIP offers an end-to-end workflow to design, optimize, deploy, and update AI/ML runtimes for a large variety of models and hardware targets whether embedded or cloud based.
If rising cloud computing costs are a concern to you, LEIP can:
- Improve model inference without requiring upgraded hardware
- Reduce operating cost without impacting your current cloud workflow
- Deploy AI/ML models to market faster with a simpler, transparent, and dedicated edge MLOps workflow
- Do it all via the same end-to-end workflow.
Ready to integrate LEIP with your SageMaker workflow? Visit latentai.com or contact us at info@latentai.com today!
Recent Blogs