Learn how LEIP streamlines edge AI development. Schedule a call today! Schedule Demo
Learn how LEIP streamlines edge AI development. Schedule a call today! Schedule Demo

The accessibility of high-end GPUs and rapid development of machine learning software frameworks (Tensorflow, Pytorch, Caffe) have enabled recent success in the deployment of deep learning applications on the cloud. Applications in video analytics, audio processing, natural language processing (NLP) are becoming popular as consumers benefit from the new user experience, driven by the power of AI.
Now, issues in data privacy, communication bandwidth, and processing latency are driving AI from the cloud to the edge. However, the same AI technology that brought considerable advancement in cloud computing, primarily through the accessibility of GPUs for training and running large neural networks, are not suitable for edge AI. Edge AI devices operate with tight resource budgets such as memory, power and computing horsepower.
Training complex deep neural networks (DNN) is already a complex process, and training for edge targets can be infinitely more difficult. Traditional approaches in training AI for the edge are limiting because they are based on the notion that the processing for the inference is statically defined during training. These static approaches include post-training quantization and pruning, and they do not consider how deep networks may need to operate differently at runtime.
Compared to the static approaches above, Adaptive AI is a fundamental shift in the way AI is trained and how current and future computing needs are determined.
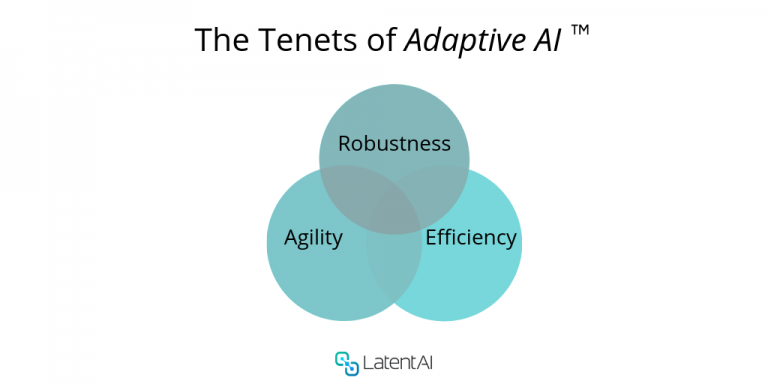
The three main tenets of Adaptive AI are robustness, efficiency, and agility. Robustness is the ability to achieve high algorithmic accuracy. Efficiency is the ability to achieve low resource utilization (e.g. compute, memory, and power). Agility deals with the ability to alter operational conditions based on current needs. Together, these three tenets of Adaptive AI formulate the key metrics toward ultra-efficient AI inference for edge devices.
At Latent AI, we use the Adaptive AI approach to adjust AI computing needs. Operational efficiency is determined during runtime in the context of what algorithmic performance is required and what computing resources are available. Edge AI systems that can dynamically adjust their computing needs are the best approach to lowering compute and memory resources needs.
Latent AI Efficient Inference Platform™ (LEIP) is an AI training framework supporting the tenets of Adaptive AI. Our first developer tool is LEIP Compress™, a new quantization optimizer for edge AI devices. LEIP Compress supports the first two tenets: robustness and efficiency through post-training and training aware quantization [1] that achieves high algorithm accuracy while reducing memory footprint and computing needs.
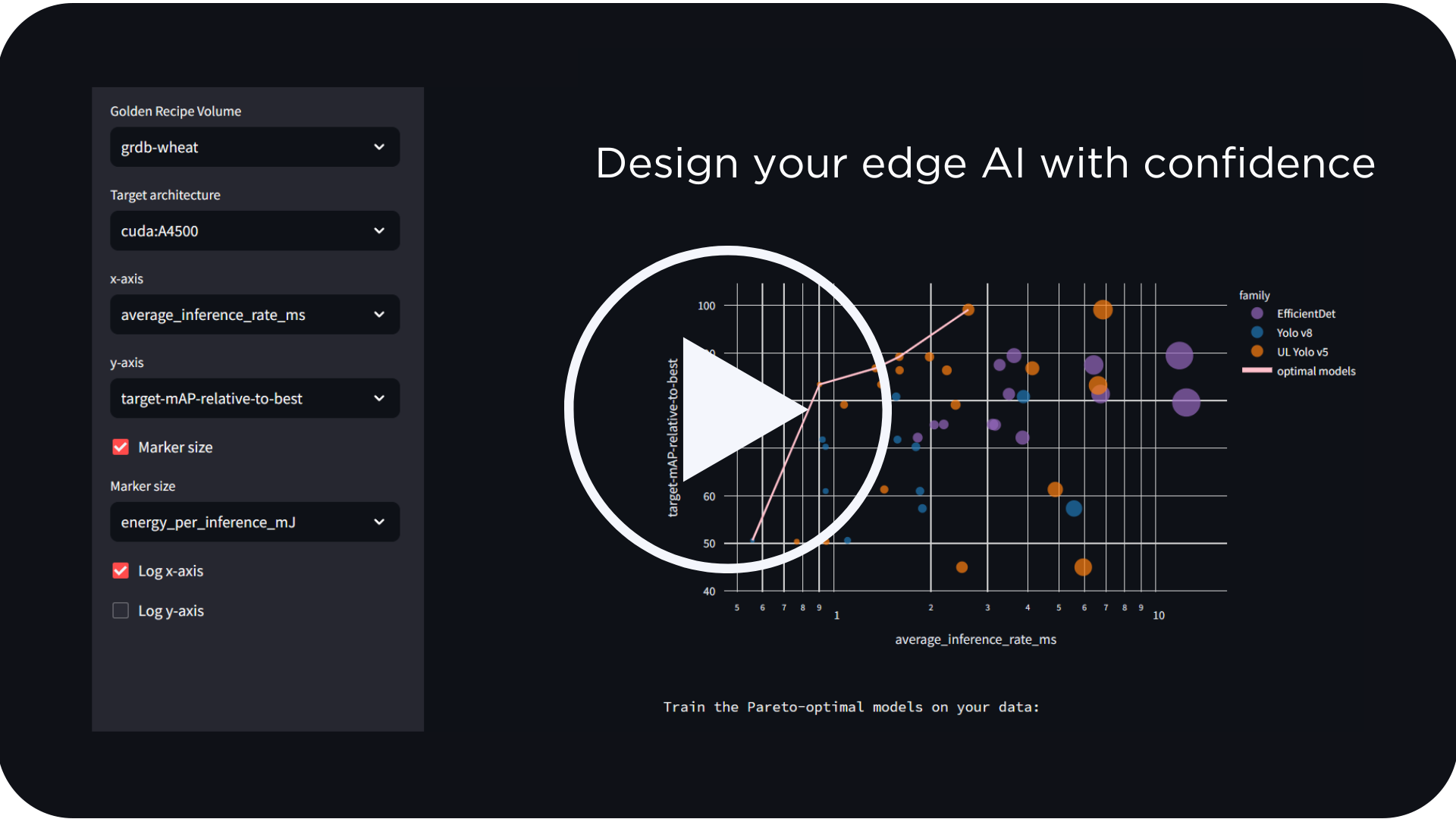
With LEIP Compress, AI developers have a newfound tool that automates the exploration of low bit-precision AI training. As shown in the example histogram of DNN parameter weights, LEIP Compress provides the means to “shape” the necessary distribution of bits in a manner that supports compression, encoding, and sparsity that are hardware-beneficial (e.g. multiplication free, power-of-two weights). Such a capability opens up the design space for high performance and efficient AI on the edge.
In summary, Latent AI aims to democratize AI training for all developers by supporting a new workflow with hardware targets in mind. We open up new application development with robust and efficient edge AI in mind. Look for upcoming LEIP frameworks that include support for agile edge inference to integrate all tenets of Adaptive AI.
Sek Chai, Co-Founder and CTO, Latent AI, Inc.
[1] Parajuli, S., Raghavan, A., & Chai, S. (2018). Generalized Ternary Connect: End-to-End Learning and Compression of Multiplication-Free Deep Neural Networks. arXiv preprint arXiv:1811.04985.

Watch how LEIP helps you start training computer vision models in minutes instead of months