



Faster time to market with Latent AI and Kili Technology, part 2

Kili and Latent AI have partnered to make edge AI easier to implement by combining high quality data with faster training, prototyping, and deployment. By combining approaches, we can forge a path toward AI solutions that not only overcome current deployment and scalability hurdles but also lay a solid foundation for the future of AI development and implementation.
Here are the technical details describing the integration process to better highlight how the respective technologies interact and function.
Requirements
- Install `kili-python-sdk` for using Kili’s API
Simply run:

For more information on getting started with the Kili-python-sdk, click here.
The Latent AI SDK is available on a set of Docker images and depending on the hardware target that you have in mind you may need to satisfy some system dependencies. The following shows an example of how to pull the container that supports a Jetson Xavier device.

For more information please follow the documentation here.
Step 1: Annotation of a dataset on Kili, followed by the export of images and their corresponding labels.
Once your dataset has been annotated on the Kili app, we are ready to export it. There are two ways to do it, either on the app or through the API. In order to provide a more automated integration we will use the functions from the Kili API in the `kili-python-sdk`.
For an easier integration, we are going to export labels in a common image format annotation such as COCO because Latent AI also supports this input format.
As a remark, both Kili and Latent AI also support PascalVOC format if you prefer.

For further information on export options with the kili-python-sdk and supported format, you can have a look at the tutorial here.
The exported data has the following format:

Step 2: Exported images & labels are ingested by LEIP tools
Latent AI has many pre-configured recipes covering dozens of image detectors and classifiers with suitable parameters for different data and target requirements. To start the process, you set a small number of parameters in a data ingest file to instruct Application Frameworks on how to use the data you exported from Kili. Templates are provided. We’ve simplified the detector dataset example below to highlight the only parameters that most users will need to provide:

Everything except the root_path is set to match the COCO dataset defaults. The folder structure is similar to the one in step 1:

In order to meet the following structure, you will have to split the exported images and annotations into train and validation subset. You can either split them with a script or export data from Kili in two steps, once by filtering with your train assets and another time by filtering with your validation assets.
Once you have created the data configuration file, you may select a starting recipe and use it to for training with the “train” command:

Once the training process is complete, you can evaluate the results with the “evaluate” command, or see predicted bounding boxes on images using the “predict” command:

The above process is easily repeated with additional recipes to find the best model that meets your data and requirements. When you are ready to test the model on the target hardware, you can export the model into a traced PyTorch file for optimizing and compiling:

You can find more details on the above commands and additional options by reading the Bring Your Own Data (BYOD) tutorial here.
Step 3: Model Optimization
One of the benefits of using Recipes is that each of the underlying models has been selected and configured by Latent AI to ensure it will optimize for edge device deployment. You may explore the ML recipe space without concern for the complexities of compiler optimizations. These optimizations include layer fusion, memory transfer reductions, quantization, among others as well as low level optimizations that depend on specific hardware targets.
Once the user has trained one or models, the Latent AI SDK allows the user to select which particular quantization as well as other compiler optimizations can be applied to those models. Latent AI can target many CPU and GPU devices but for this example let’s target a Jetson Orin device using Jetpack 5.0. Here we provide a pipeline configuration file that instructs the compiler to use symmetric per channel quantization and to employ Tensor RT as part of the back end optimizations.

In the directory specified as ”output_path” above the compiler will create several subdirectories with generated artifacts:

The packaged LRE object supports options such as encryption and packaging of components such as pre- and post-processing and dependencies, while the -compile and -optimize directories contain the bare model executable. In either case, the model files are compatible with the Latent Runtime Engine (LRE).
Step 4: Deployment
Deployment is where you decide what and how you want to bring the ML model as part of your application. For this example let’s assume that you read an image from a file residing on the Jetson Orin and that you output an image with the bounding boxes to an attached monitor. You can easily read an image from a camera sensor if you want because the example inference script supports OpenCV.
Latent AI provides several examples on how to integrate the LRE into your application. The examples are in Python and C++ and you can find them in this GitHub repository here.
We won’t go into the actual deployment code but suffice to say that the output of the inference script is an image with bounding boxes drawn on top of it. The image also contains the class name and confidence values. Values of the anchor box coordinates, class names and confidence values as numpy arrays are also provided by the inference script.
Step 5: A process to identify images with incorrect predictions, sending them back to Kili for reannotation
Before deployment the model designers encode a set of rules describing the range of values of what they expect to detect at inference time. For example on a factory floor they may expect to find a fixed number of pieces on the scene, each within a bounding box with a certain range of variations. The expected range of these variations is called the distribution.
At inference time if the output falls outside of the expected range of values the LRE can be programmed to send the input image, processed output image, and the bounding box coordinates (anchor points) plus the inference accuracy back to a server. The server collects these out of distribution images, packs them, and sends them for data analysis.
To send new assets to Kili, we will use the SDK’s `append_many_to_dataset ` function:
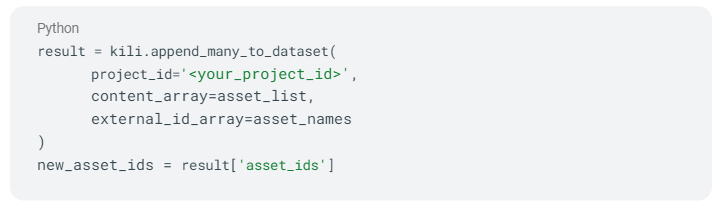
where:

In order to also import the predictions made by the model, we will use the SDK’s `create_predictions`:

where:
- `labels_list` is the list of annotations in the Kili format.
You currently cannot import labels directly in the COCO format so you will first need to convert them in the Kili format. Please follow the tutorial here if you are interested in doing this step.
Step 6: New annotations being performed on Kili, a continuous loop, restarting the process
You can now start back from Step 1, annotating the new images on Kili, exporting them and retraining a model on Latent AI with the new training data.
Conclusion
While the digital world is moving from a code-centric to a data-centric paradigm, building high quality datasets and deploying them on the edge remains a complex task. Engineers all around the world are looking at the best ways to build their data labeling and deployment pipeline and learn about best practices others have discovered through trial and error.
Kili Technology, with their relentless focus on data labeling efficiency and quality, and Latent AI, with their dedicated MLOps processes that support rapid prototyping and delivery of optimized and secured models , are two great players to help structure your ML processes and deliver high-quality AI.
For more information about Latent AI products and services, visit Latent AI Products.
For more information about Kili Technology and the importance of high-quality data, visit Kili Technology.
Recent Blogs