



Federated learning: Balancing collaboration and privacy in the digital age

With user data, comes great responsibility
From kindergartners picking up behavioral skills in the playground to developers using stack exchange to debug code, sociology tells us that humans are constantly learning from each other. If the goal of artificial intelligence (AI) is to imitate and ultimately supersede human intelligence, it only makes sense to utilize collaborative learning techniques to improve AI’s capability. By leveraging collaborative learning techniques, data can be aggregated from many sources to build the highest quality model much more quickly. But what if data privacy is also a concern? There is a solution that balances collaborative learning techniques with data privacy and security. Federated Learning is a domain of AI that enables collaborative learning while maintaining user privacy.
How does Federated Learning work?
Suppose you want to develop an AI model that successfully detects cancer using patient records (blood samples, X-rays, etc.) as inputs. A larger amount of data would improve the success rate of detection. However, this data is spread across hospitals that do not want to share patient records due to patient confidentiality and HIIPA laws. Federated learning offers a solution to sharing the knowledge from the patient records without sharing the records themselves. Here’s how it’s done:
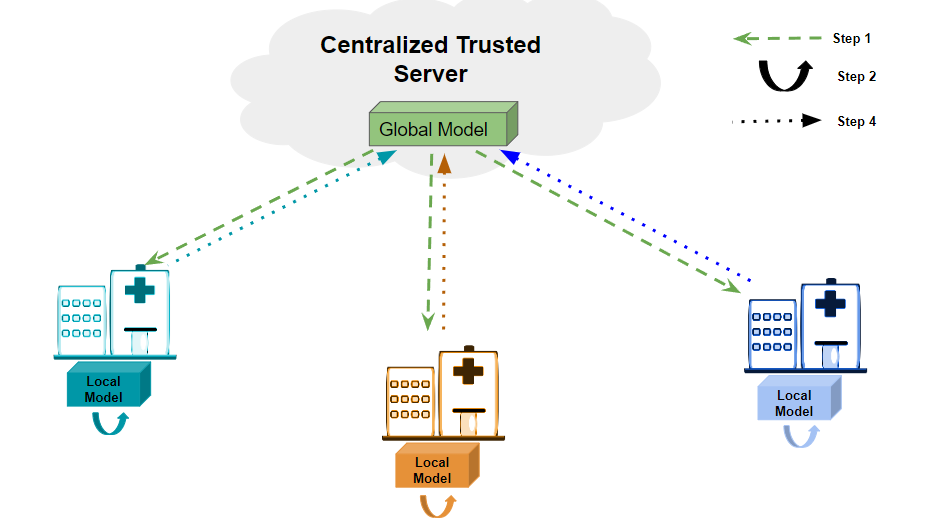
A centralized trusted server maintains the AI model. This model (referred to as a global model) is transferred (shown as Step 1 in the image) to all the participating hospitals. The hospitals each train their model (referred to as local models) on the private data available locally (shown as Step 2). They then calculate the difference between the global and their local model parameters (Step 3 referred to as the weight update not shown in diagram), and communicate these weight updates to the centralized server (shown as Step 4). The centralized server then averages these weight updates and updates the global model. This entire process is repeated in a continuous cycle until the model converges to provide a satisfactory performance.
Is there a need to optimize Federated Learning?
Each round of federated learning requires two rounds of communicating model parameters (once from the server, Step 1 and then to the server, Step 4). AI model sizes have been growing exponentially, from AlexNet in 2012 (60 million parameters) to GPT2 in 2019 (1.5 billion parameters) to GPT4 in 2023 (170 trillion parameters). This large exponential growth (surpassing even Moore’s law with a greater rate of innovation) creates an increase in the communication payload (the data size and transfer time over communication mediums, e.g. WiFi, BLE, cellular data) in federated learning systems. This acts as a bottleneck in edge devices, the ones that most commonly have access to user data, as there is limited bandwidth and compute power.
For example, GPT2 has a communication payload of 5.58 GB (size of data to be transferred per communication). Practitioners and academics have noted that it takes around 50M pieces of data to create a 60%-70% performant model. If we assume 1MB per datum, communicating the data by itself would have a communication payload of 50TB. Thus in addition to providing privacy, the approach of sharing model parameters can greatly reduce the network bandwidth requirements. With higher bandwidth, such as 10GigE speeds, it would only take 3.6s to transmit 1GB worth of data. However, in scenarios where the edge devices are deployed in remote locations, the bandwidth available is small. For example, 3G cellular networks offer an average of 3Mbps, and tactical radios, when being denied or contested, provide only very limited bandwidths, perhaps only 10-100Kbps. This implies that even communicating the model parameters (while being more efficient than communicating the data itself) needs to be optimized to make an optimal usage of bandwidth and add minimal time overhead due to communication.
Why Federated Learning means speed plus privacy
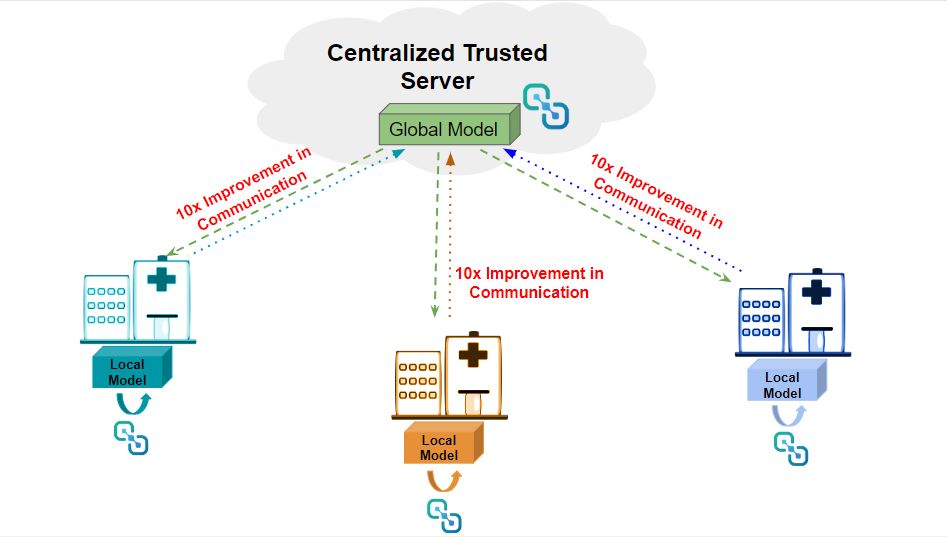
The next goal in federated learning is to make models smaller and communicate optimized parameters while still sharing enough information for the global system to learn the task at hand. The Latent AI Efficient Inference Platform (LEIP) already provides a platform that can efficiently optimize and compress the model parameters by 10x or more. Utilizing our platform not only alleviates the communication burden on these devices but also reduces the computational and memory requirements of the AI model.
For example, in the hospital scenario, we can deploy the LEIP platform at the hospitals as well as the centralized server. Instead of communicating uncompressed weight updates (that can exceed millions of parameters and megabytes of data communication), we can communicate the compressed model weight updates. This reduction in bandwidth alone can significantly speed up the federated learning process.
The future of AI is in edge devices and making efficient use of data. Enabling collaborative frameworks on all types of devices will play an excellent role in progressing research in AI.
Recent Blogs