

DevOps for ML Part 1: Boosting model performance with LEIP Optimize
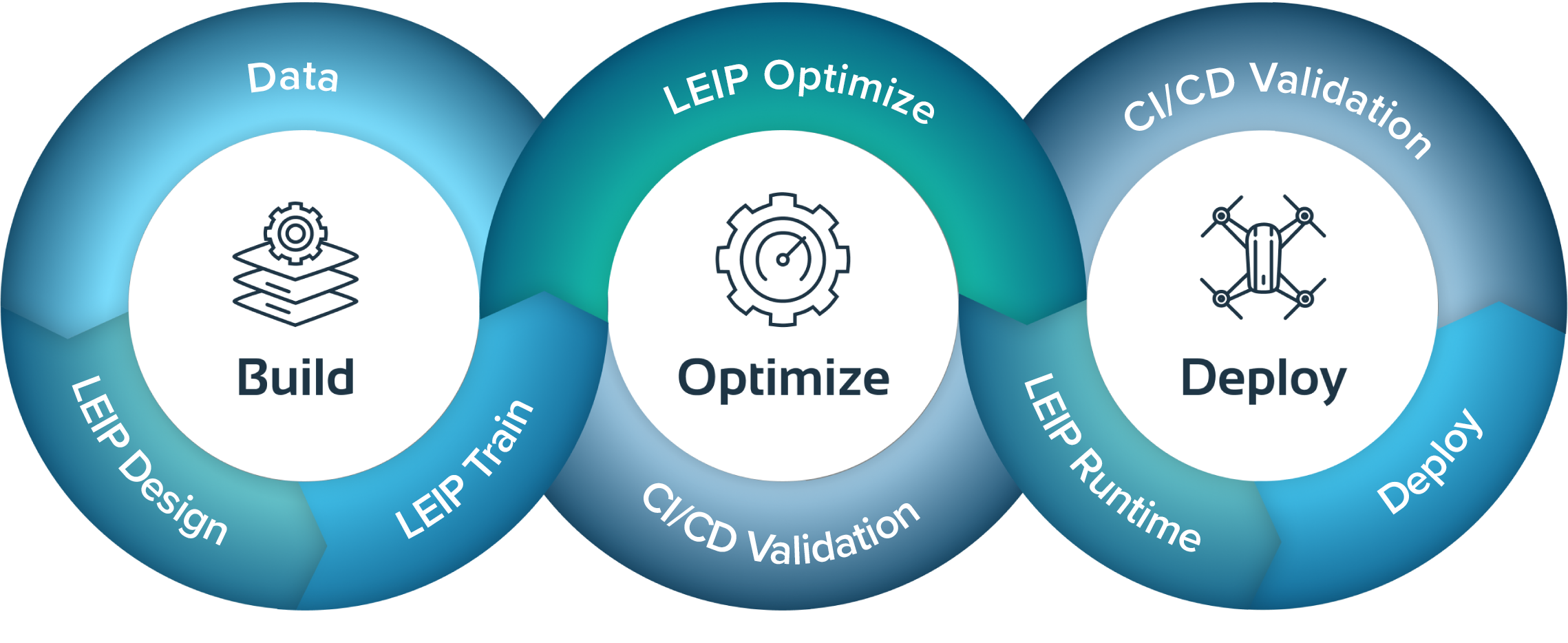
The Latent AI Efficient Inference Platform (LEIP) creates specialized DevOps processes for machine learning (ML) that produce ultra-efficient, optimized models ready for scalable deployment as executable files.
But how does it work? How does AI actually go from development to deployment to a device? In this series of blog posts, we’ll walk you through the ML life cycle and show you how LEIP can take you to market faster.
LEIP Optimize
Boosting model performance for the edge begins with LEIP Optimize, one of the core modules of LEIP. It is the first step in the LEIP software development kit’s (SDK) end-to-end workflow. LEIP Optimize allows an ML developer to take their pre-trained models and configure them for optimal performance on specific hardware. This involves quantizing the model to specified values and observable quantities, resulting in a Latent AI Runtime Engine (LRE) object that is tailored to the developer’s requirements. The optimized model includes executable code that is designed to function seamlessly with the target hardware, ensuring efficient and effective execution.
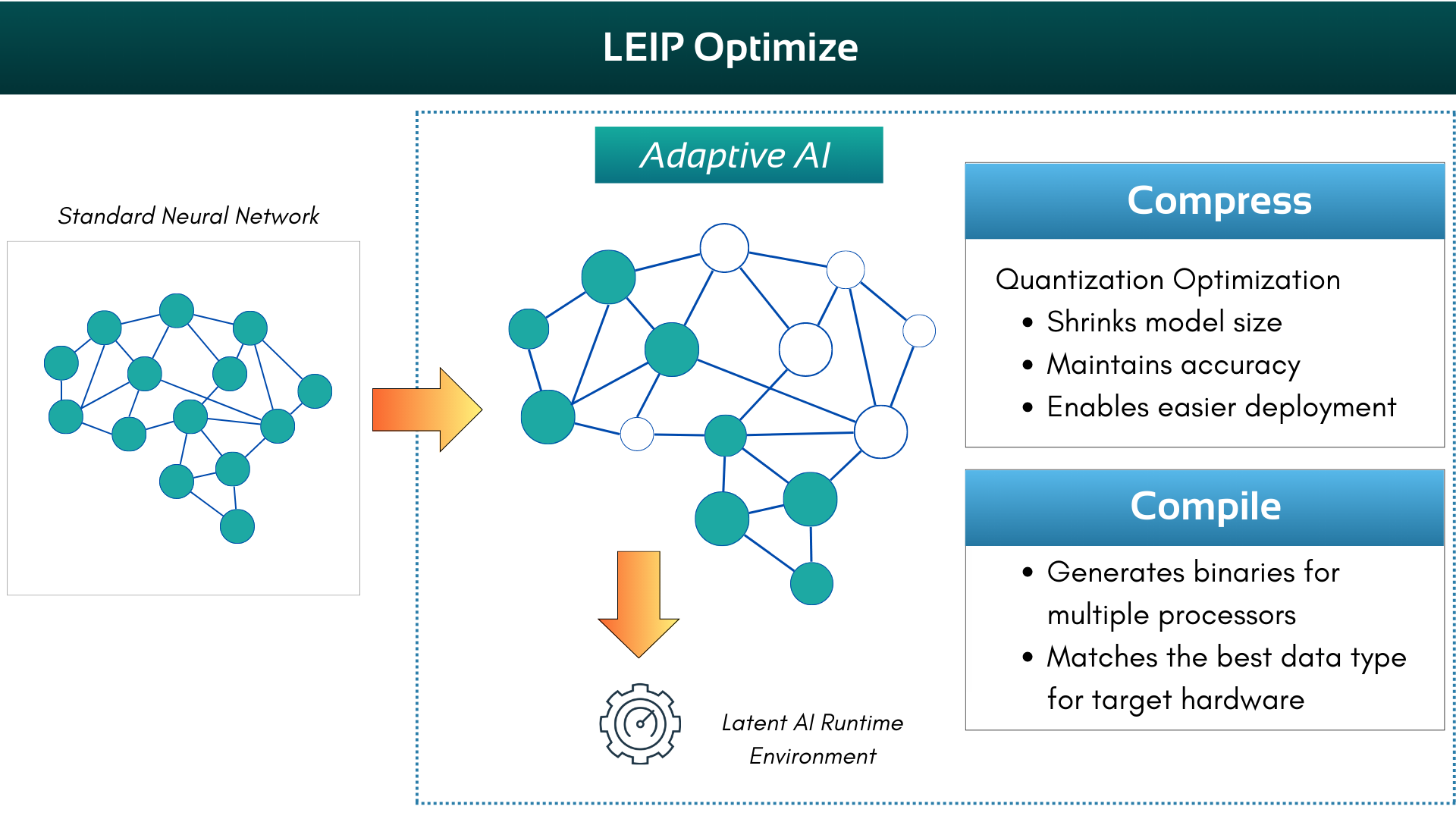
There are two phases to LEIP Optimize – LEIP Compress and LEIP Compile.
LEIP Compress
To understand how LEIP Compress functions, we have to have an understanding of neural networks. At its core, a neural network is a technology designed to mimic the human brain’s pattern recognition and information processing capabilities. It consists of an input layer, an output layer, and at least one hidden layer in between. The term “deep learning” is often used to describe neural networks, as they represent a sophisticated form of machine learning that use aspects of artificial intelligence to classify and order information in ways that go beyond simple input-output relationships. Deep neural networks use a large number of specifications to perform their functions, which can significantly impact their resource requirements. This often makes them too large for deployment on edge devices.
LEIP Compress addresses this challenge by applying quantization optimization to reduce the model’s size. Quantization involves analyzing the distribution of floating-point values and mapping them to integer values while minimizing accuracy loss. This optimization technique makes it significantly more feasible to deploy the model to edge devices.
In addition to quantization, LEIP Compress offers two other optimization methods: Tensor Splitting and Bias Correction. Tensor Splitting allows for more flexible compression ratios by splitting tensors within the model. The algorithm automatically determines which layers are suitable for splitting, optimizing the process. While Tensor Splitting can take several minutes to complete, especially for large models, it can yield substantial benefits.
Bias Correction is another valuable optimization technique. It involves introducing a controlled error to the outputs to calibrate the model and eliminate the error. This calibration can significantly enhance the model’s overall performance.
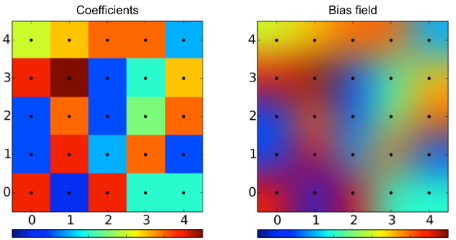
Figure 1. Bias Correction. Regularly spaced coefficients (left) and interpolated bias field (right). (Illustration from Wikipedia)
LEIP Compile
LEIP Compile is the final step in the optimization process. It takes the compressed model (computational graph) as input and generates a binary image tailored to the specified target architecture. This binary image, a shared object file, is designed to be loaded onto a runtime for execution.
LEIP Compile can apply various optimizations to the computational graph to enhance performance. However, these optimizations can be computationally intensive. To balance optimization with efficiency, the compiler defaults to standard optimizations.
LEIP Compile supports a wide range of processors, including x86, NVIDIA, and ARM architectures. It can generate binaries for different data types, including 32-bit floating point, 8-bit integer, and mixed types. The compiler intelligently selects the most suitable data type based on the target hardware’s capabilities, ensuring optimal performance.
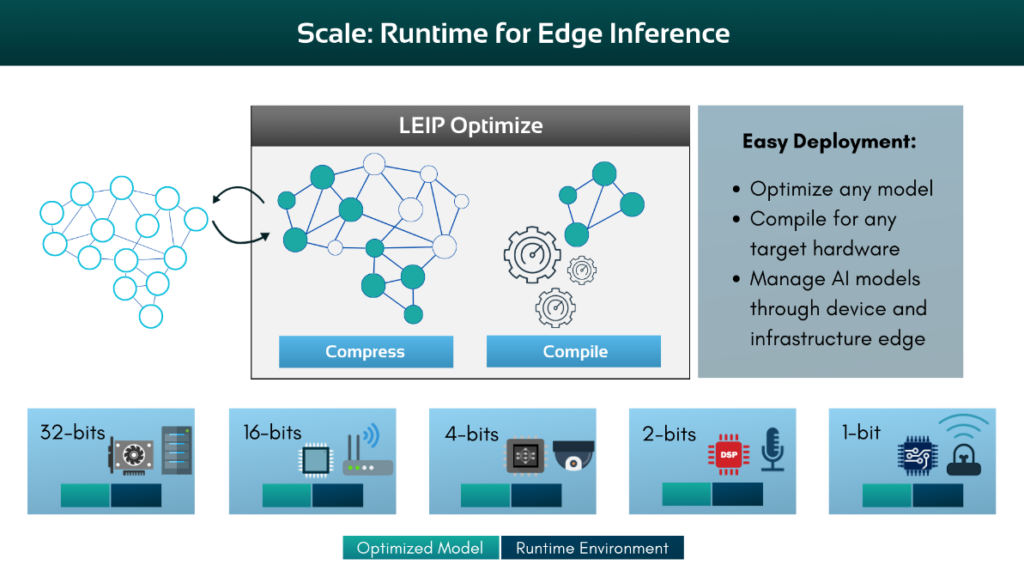
Once a model is optimized, the next step will be to evaluate its accuracy throughout the different stages of the LEIP process. LEIP Evaluate is an essential tool for assessing model accuracy throughout the LEIP optimization process. By using LEIP Evaluate, you can consistently measure and track the performance of your model across the entire machine learning development lifecycle.
In our next post, we’ll discuss LEIP Evaluate and how you can use it to ensure the accuracy and reliability of your optimized models across the entire ML development life cycle.
For our Documentation of the LEIP SDK User Guide and LEIP Recipes, visit our Resource Center. For more information, contact us at info@latentai.com
Recent Blogs
